
25-01-2021
Como implementar Service Discovery com Spring?
Com a recente evolução de novas arquiteturas é muito comum depararmo-nos com novos problemas e desafios. Estes requerem soluções inovadoras para tornarem a arquitetura mais robusta e fácil de manter e evoluir.
A transição de arquiteturas tradicionais, baseadas em monolitos, para arquiteturas baseadas em microserviços, que tornam as soluções mais resilientes e elásticas, é acompanhada por um desafio fundamental de gestão. O que antes era uma peça singular, coesa e interligada, passa agora a ser um conjunto de peças heterogéneas que requerem intercomunicação entre si.
Mas o que é que caracteriza fundamentalmente cada um destes tipos de arquitetura? Como implementar Service Descovery com Spring?
Arquitetura monolítica
A arquitetura monolítica está presente desde os primórdios dos sistemas de informação e ainda é, aos dias de hoje, um estilo arquitetural bastante usado especialmente por produtos proprietários off-the-shelf, que herdam um histórico legacy significativo de código em cima de código (e que, portanto, não é fácil nem barato de alterar). Mesmo possuindo a conhecida decomposição em tiers – que tipicamente incluem uma ou mais interfaces, uma camada aplicacional, uma camada de acesso a dados e a persistência dos mesmos – o desenvolvimento de novas funcionalidades é feita verticalmente, em bloco.
Esta essência inerente oferece alguns pontos positivos, tais como menos preocupações transversais (todos os módulos têm, de alguma forma, dependências e ligações fortes entre si), a facilidade na depuração e realização de testes funcionais (visto que as funcionalidades “falam a mesma língua” e atravessam os mesmos componentes) e a simplicidade na gestão de deploys (pois o sistema apenas é composto por uma ou um conjunto limitado de peças).
Porém, as desvantagens destas arquiteturas limitam em muito a flexibilidade e agilidade que hoje em dia são exigidas às organizações. Por um lado, a escalabilidade é limitada, já que a redundância do sistema é obtida à custa da replicação na sua totalidade ou de uma grande fatia do mesmo. A criticidade de introdução de alterações é outra dos problemas inerentes, já que o deploy torna-se mais “pesado” e, ao ser feito em bloco, afecta e pode impactar a funcionalidade geral do sistema. O desenho dos serviços e funcionalidades está restrito a um modelo fixo, pré-concebido de raiz, podendo condicionar a flexibilidade e performance da solução. Por fim, estas soluções têm uma fraca versatilidade tecnológica, pois limitam o desenvolvimento às tecnologias e linguagens de programação definidas para a solução (e que algures no tempo poderão ter limitações ou tornar-se obsoletas).
Arquitetura de microserviços
As arquiteturas baseadas em microserviços são mais recentes, e embora já tenham alguns anos apenas nos últimos têm sido alvo de uma adoção mais generalizada, fruto da maturidade e provas que têm demonstrado. O conceito fundamental de uma arquitetura deste tipo é o da separação do desenvolvimento da solução em peças isoladas, de menor dimensão, com uma responsabilidade e propósito específicos (os microserviços).
In short, the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies.
– James Lewis and Martin Fowler (2014)
As grandes vantagens destas arquiteturas são o isolamento entre componentes, fornecendo-lhes autonomia suficiente para terem ciclos de vida independentes para responderem às necessidades dos seus stakeholders, e a alta escalabilidade, já que é possível gerir a resposta às necessidades de carga ao nível de cada microserviço (e não da solução inteira). Outras vantagens incluem: a agilidade, visto que esta arquitetura facilita e promove a experimentação e prototipagem; a heterogeneidade tecnológica, já que a cada microserviço apenas se requer que seja comunicante, podendo ser desenvolvido em qualquer tecnologia ou linguagem de programação que melhor dê resposta à necessidade em concreto; a facilidade de compreensão, pois a solução é desenhada da forma mais clara e “limpa” com fronteiras de responsabilidade bem definidas entre componentes.; e a resiliência, pois é possível construír sistemas que consigam tolerar a falha total de serviços, degradando a funcionalidade do sistema aos poucos e não como um total.
Apesar destas vantagens serem muito relevantes no contexto atual, existem algumas condicionantes e dificuldades que devem ser endereçadas para que se consiga implementar e manter com sucesso uma arquitetura baseada em microserviços. A complexidade de gestão é das mais importantes, visto que a solução é composta por múltiplas peças com diferentes características, pelo que são exigidos níveis elevados de automação dos processos. Outro desafio muito importante é a distribuição dos componentes, que dada a sua granularidade e propósito arquitetural deixam de ter de estar presos a uma só localização e podem escalar de forma independente. Por fim, outras das grandes dificuldades é sentida durante a realização de testes funcionais às aplicações, visto que cada circuito pode atravessar múltiplos microserviços desenhados com comportamentos diferentes.
Face a esta natureza da solução um dos grandes desafios é a gestão da localização de cada um dos microserviços. Como tal, uma das boas práticas das arquiteturas baseadas em microserviços é a da determinação automática da localização do serviço, funcionalidade que é conhecida como service discovery.
O que é o Service Discovery?
O service discovery é a funcionalidade que permite abstrair a implementação de uma solução da localização dos recursos (serviços) que pretende consumir. Visto que um microserviço pode estar a ser executado em múltiplas localizações, e que as mesmas não são fixas e podem variar consoante o scale-in e scale-out do microserviço, é necessário dar a capacidade às aplicações de descobrirem onde está o microserviço a que pretendem aceder.
O processo é relativamente simples:
- A instância de serviço, ao iniciar-se, regista-se no directório de serviços com a sua localização corrente. Um serviço é identificado com um nome lógico, pelo que múltiplas instâncias do mesmo serviço registar-se-ão com o mesmo nome, estando representados desta forma em múltiplas localizações.
- O subscritor do serviço faz uma consulta ao diretório pelo nome lógico do serviço a que pretende aceder. O diretório devolve todas as localizações conhecidas do serviço.
Fica a cargo do subscritor, depois, decidir qual a localização a que pretende aceder. Esta funcionalidade pode, posteriormente, ser combinada com um mecanismo de load balancing para gerir este acesso de uma forma mais eficiente.
Existem várias implementações do service discovery, sendo o Eureka (Netflix) e o Kubernetes (Google) duas das mais conhecidas.
Exemplo prático: Como implementar Service Discovery com Spring?
Para a criação, configuração e implementação de um exemplo demonstrativo da funcionalidade de service discovery podem ser utilizadas as seguintes frameworks e ferramentas:
- IntelliJ IDE
- Spring Initializr
- Spring Boot
- Spring Cloud
- Eureka Service Discovery
- Maven
1. Criar o serviço de service discovery
Para os efeitos desta demonstração irá ser utilizada uma implementação de service discovery disponibilizada pela Netflix: o Eureka.
Será necessário criar um servidor Eureka que disponibilize todas as funcionalidades de registo e pesquisa de serviços. Para tal, deve ser criado um projeto com o nome DemoApplication através da ferramenta Spring Initializr.
Este projeto apenas requer a adição de uma única dependência: Eureka Server.
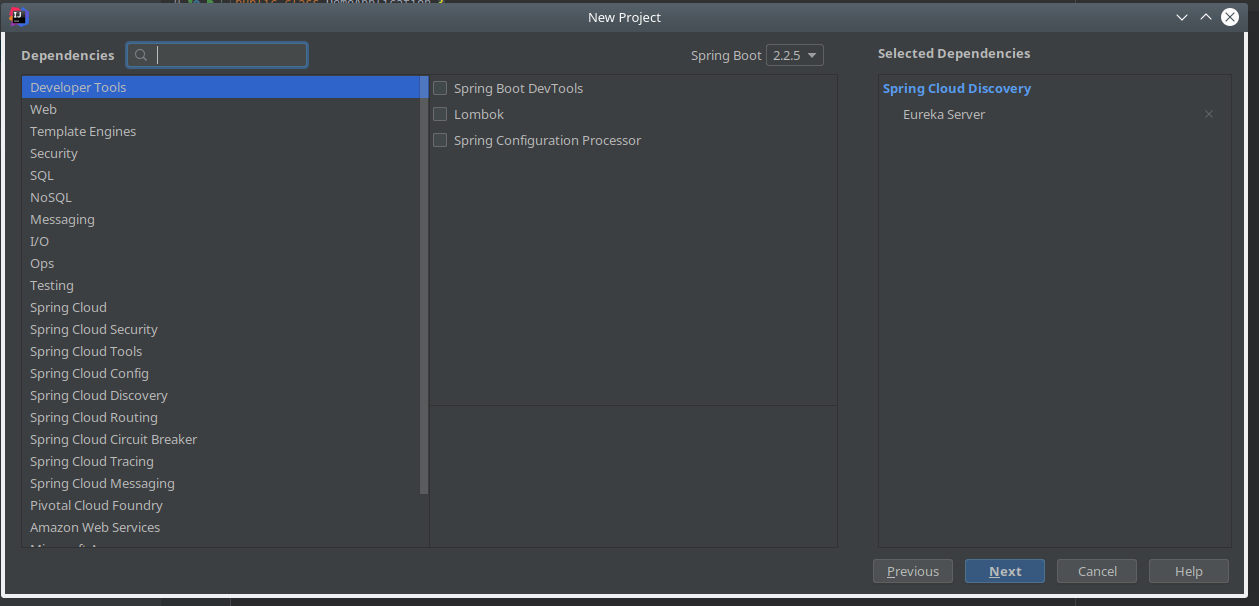
Assim que o projeto estiver criado é necessário configurar dois ficheiros: o application.properties e a classe de inicialização do Spring Boot para implementar o service discovery com Spring.
DemoApplication
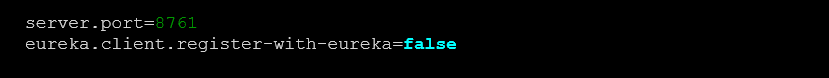
Code Block 1 application.properties
Este servidor irá ser servido no porto 8761. O código da aplicação apenas necessita de incluir a anotação @EnableEurekaServer para habilitar o servidor Eureka.

Code Block 2 DemoApplication.java
2 – Criar os microserviços
É necessário criar dois projetos para os microserviços que se comunicarão entre si com o auxílio do service discovery com Spring. Os serviços são designados de Demo1, o consumidor, e Demo2, o fornecedor.
Os mesmos apenas requerem a adição de duas dependências através do Spring Initializr:
- Spring Web
- Eureka Discovery Client
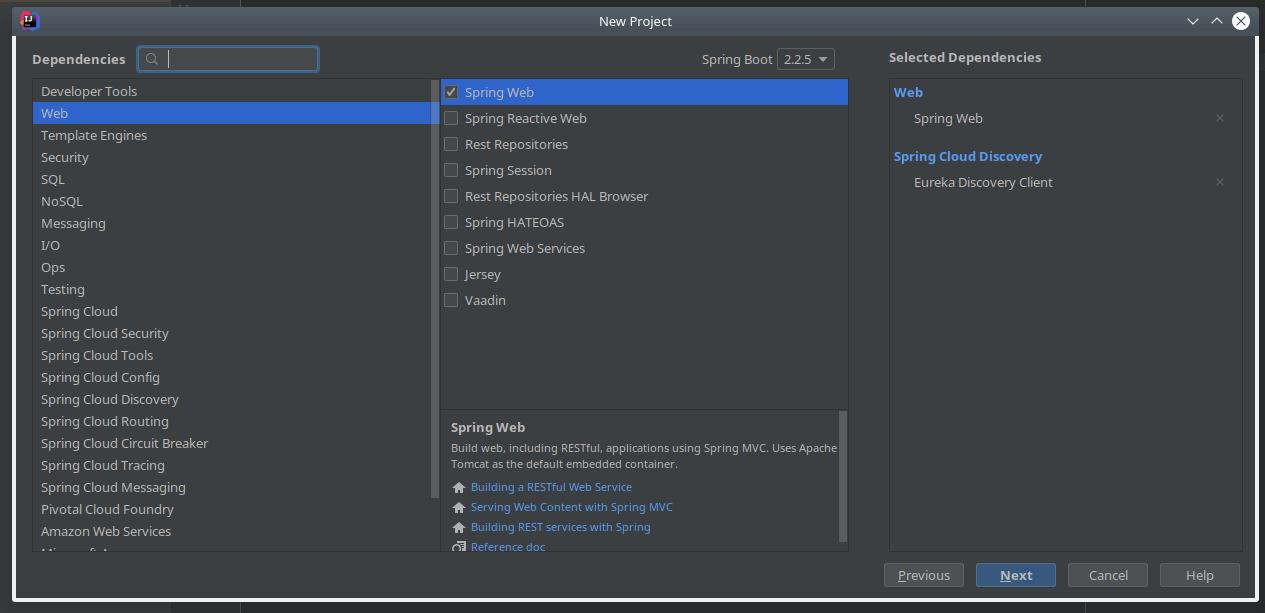
Depois de criados os projetos, é necessário configurar o ficheiro application.properties de cada um dos serviços.
Demo 1

Code Block 3 application.properties
Demo 2

Code Block 4 application.properties
3 – Inicializar os Serviços
Após a criação de todos os projetos pode-se, então, inicializar os mesmos na seguinte ordem:
- DemoApplication (Eureka server)
- Demo2 e Demo1 (Eureka clients)
Após a sua inicialização os serviços Demo1 e Demo2 deverão ter-se registado com sucesso no diretório de serviços (Eureka server).
Para validar o sucesso do registo basta efetuar um pedido ao Eureka server //localhost:8761/eureka/apps e confirmar que os serviços estão listados.
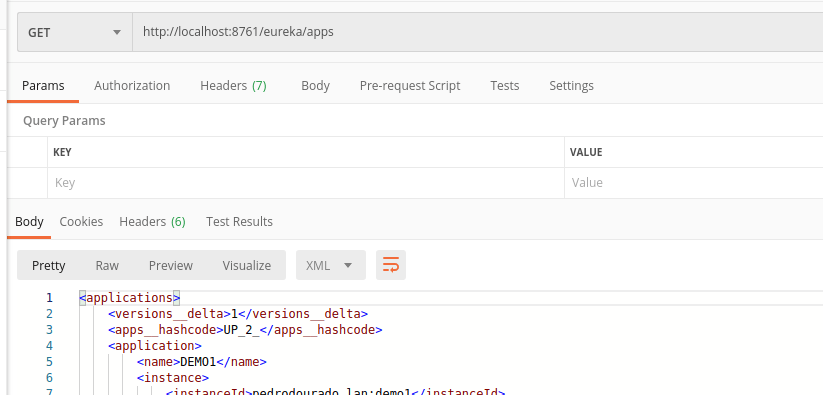
4 – Implementar a invocação entre os serviços
Confirmado o funcionamento do service discovery com Spring, resta então implementar a invocação do serviço Demo2 por parte do serviço Demo1 tirando partido desta funcionalidade.
Para tal, deverá ser criada no projeto do serviço Demo1 uma classe DemoController que utilize o RestTemplate para realizar a chamada HTTP ao serviço Demo2.
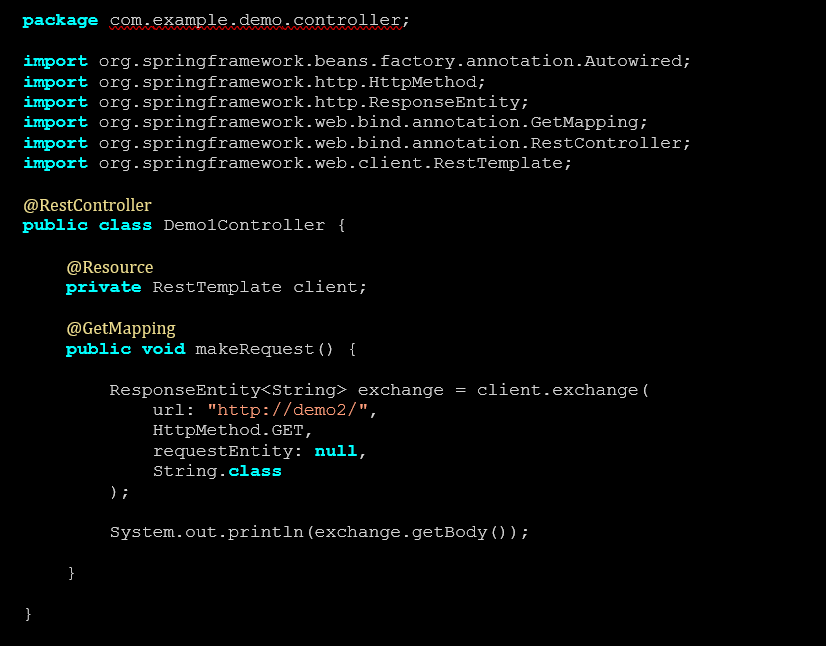
Code Block 5 Demo1Controller.java
De seguida, é necessário adicionar o RestTemplate como bean gerido pelo Spring. A anotação @LoadBalancer informa o Spring Cloud para a utilização do seu suporte de balanceamento de carga (fornecido, neste caso, pelo Ribbon).
Para isso, basta adicionar o seguinte código na classe de inicialização do Spring (DemoApplication).

Code Block 6 DemoApplication.java
Posteriormente, no projeto do serviço Demo2, deve ser criada uma classe RestController com o seguinte código para tratar a chamada ao serviço.
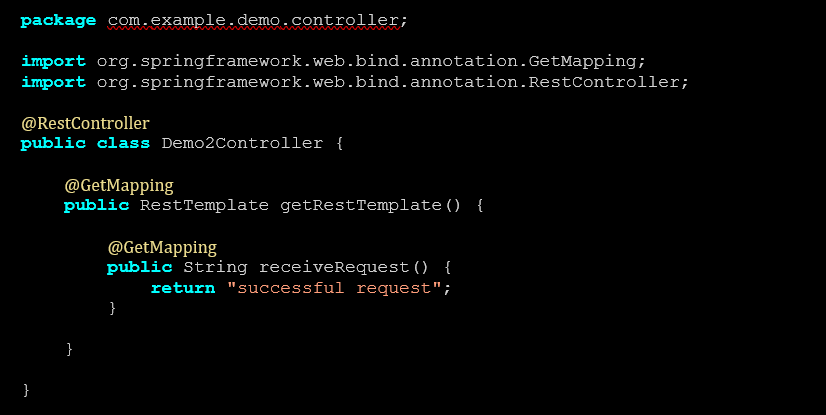
Code Block 7 Demo2Controller.java
5 – Testar a invocação via service discovery
Finalizadas estas configurações, basta reiniciar os projetos e fazer um novo pedido a //localhost:8080.
Na consola conseguir-se-á confirmar se a invocação do serviço Demo2 a partir do serviço Demo1 via service discovery foi bem sucedida (“successful request”).

























Leave a comment
Comments are closed.